Your Own Customers Will Disrupt You With AI

If you haven’t already, check out my book, Founder Unfriendly: What Investors Won't Tell You About Getting Funded and my new AI fundraising coach and companion guide.
_____
Strava's AI just told me I crushed the NYCRUNS half marathon in Brooklyn with my 1:35. It said I “sustained high intensity throughout with impressive heart rate effort.” I got similar feedback when I ran the NYRR NYC Half.
Not true.
In reality I’m in a slow recovery from from a torn proximal hamstring tendon and I haven’t been able to pinpoint why I just wasn’t running at the speeds I wanted to, despite feeling like I’m in good shape. It felt like I had another gear that I just wasn’t able to shift into.
I took my Strava data from these races, along with peak previous performances on the same course, and uploaded it to Claude with the following prompt:
“I would like you to compare two sets of races on the same course... the Brooklyn Half and the NYC Half. 2026 times are after a torn tendon (ischial tuberosity). Is there any insight you have into what's hindering me in this post-tear recovery?”
A minute later, I had charts, insights and the ability to query it further.
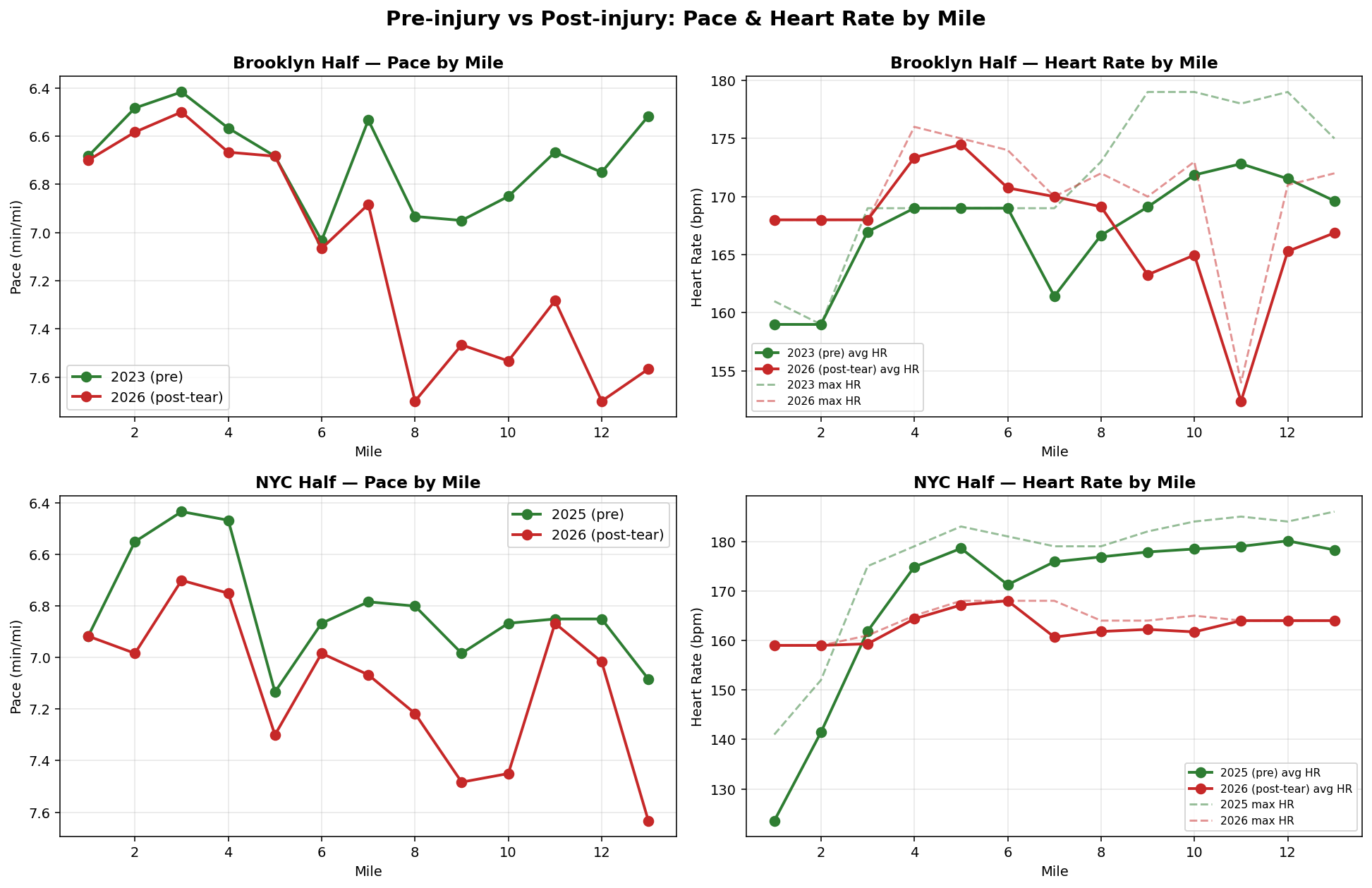
The charts told the story across both races: I ran nearly four minutes slower at Brooklyn than I did pre-injury and almost six minutes slower at NYC. My pace didn't sustain — it collapsed in the back halves of both. The heart rate effort wasn't impressive, it was suppressed: my max HR in NYC was 168, twenty-two beats below my pre-injury max on the same course, and my average HR across both post-injury races was actually lower than in previous races, not higher.
Strava's sentence contradicts the data Strava parsed to write it.
The aerobic base is intact, but the ceiling collapsed (max HR way down across both post-injury races). The fade compounds in late miles, gets worse on hills, and there's a tell at mile 11 of Brooklyn where my HR dropped to 152 on a flat stretch — which means the bottleneck isn't cardiovascular, it's neuromuscular.
Probably some mix of actual inhibition and a subconscious unwillingness to fully load the hamstring. I asked it, “Is it a lack of trust in my hamstring?”
It said this:
“A few things in your data make me think it's partly trust but not entirely:
The mile 11 Brooklyn data point — 7:17 pace, HR 152, no hill — is interesting. If it were pure protection, I'd expect HR to stay elevated (you're trying, the muscle is just guarding). Instead HR fell off a cliff. That looks more like "the system disengaged" than "I'm consciously holding back."“
It even suggested a specific workout I could run to differentiate the two.
That's an incredibly useful piece of analysis. It tells me what to bring to my trainer.
Strava only told me I was a champ. Womp. Womp.
Here's the part that should bother everyone established at the top of their category right now: Strava had everything Claude had and more. Years of my training history. Heart rate trends. The same course from last year. My recent volume, my old races, my injuries embedded in the titles and descriptions of races.
They had all the data and produced a fortune cookie. Claude, given four files and a question, produced actionable insight.
Similarly, my friend Margot Mazur posted last week about giving up on Duolingo after ten years and building a Spanish tutor on Claude in a weekend. Hers asks her questions about organic agriculture, local food culture, wine, and Mexican history — all things she actually cares about — instead of teaching her to say "the rabbit is eating an apple."
It tracks where she keeps slipping up. It recommends a podcast or a film at the end of each session. She says it's better than any language tool she's ever used, including the ones she's been paying for.
Duolingo should have built that. They've had her error patterns, her engagement history, her stumbles and her wins, for a decade. They had every piece of information needed to make Margot's tutor—all they needed was a scan of her Instagram for interests, and yet they shipped a green owl that guilts her instead.
Classic innovator's dilemma — except AI changes one thing about the dynamic that I don't think most incumbents have internalized yet:
AI makes the competition your own users.
Christensen's original frame was disruption from below by smaller, scrappier competitors. The threat was someone you could see — another company, a startup, a new entrant. You could at least watch them. Now the threat is invisible. Your most engaged user, the one paying you the most and the one who actually understands what they want from your product — they can build a version that beats yours over a weekend, for peanuts. They don't need to start a company. They don't need to raise.
The defense isn't more AI features. The defense is actually using what you know about the user.
If you're building an AI product right now, the bar is not "we have AI." Every product has AI. The bar is: did you use what you know about this specific person, on this specific day, with this specific history, in a way that makes them feel seen? Or did you ship a generic congratulations?
Strava had prior year's race times on the same course. They had my HR profile. They had a multi-month gap in my training history that lines up with exactly the kind of injury I've been mentioning in my own race titles and descriptions for months. None of that requires a structured "injury" field — a model trained on this data should be able to read it.
They shipped "you crushed it."
That's not an AI problem. That's a "we didn't actually look" problem.
Matt Slotnik (h/t Yoni Rechtman for the share) wrote a piece this week diagnosing the same problem in the public software markets, and his prescription is the right one. Incumbents have to build — but not in the measured, multi-year roadmap way they're used to. Take real free cash flow, stand up a small empowered labs group with an actual CEO mandate, and let it ship for the install base unencumbered by existing offerings, pricing, or messaging. No sacred cash cows. Compensation structures have to change. Talent assessment has to change.
Because, in Slotnik's words, “Prevent defense never works.”
Even Anthropic and OpenAI run labs efforts. The companies actually on the frontier know the frontier moves, and that building unencumbered by the past is how you stay ahead. The companies not on the frontier are running multi-year roadmaps in a world where the frontier shifts every six weeks.
That's not a strategy. That's a way to look surprised on your next earnings call.
Margot is going to keep her Claude tutor. I'm going to keep using Claude to read my training data. We are both, for now, still paying Strava and Duolingo, because the data lock-in is real and the migration cost is non-trivial. But every month, the gap between what these platforms could do with our data and what they actually do widens, and the cost of routing around them keeps dropping. Strava for example, doesn’t support multi-sport natively. I started thinking about vibe coding my own multisport Apple Watch app.
How long before I start selling it to other triathletes and packaging it with much better analysis? I could probably have it done in a week.
The first incumbent to actually do what Slotnik's describing — take real cash flow, build a labs group with teeth, and ship something that genuinely understands its users — is going to look like a genius. The rest are going to find out what it feels like when the disruptor is the paying customer.